A new era of data privacy choices

A new era of data privacy choices
August 1, 2022 | By Jeanine Miklós-Thal
Firms and government organizations are collecting data about individuals on an unprecedented scale, and nothing is off limits. Using increasingly sophisticated machine learning and AI algorithms, they analyze mountains of browsing data, social network data, location data, voice data, and contact information that we share, sometimes unknowingly, through our devices. From there, they make conclusions about our personalities, preferences, moods, and beliefs that inform a range of decisions, from advertising and marketing to hiring a candidate.
Some types of data are more privacy-sensitive than others. For example, most people might be unconcerned if a company has access to data on their favorite type of flower or their favorite band, but very concerned if a company has access to data on their sexual activity or health status.
This division of data into that deemed sensitive and that not deemed sensitive is challenged by advances in machine learning and predictive analytics. This is because advances in prediction and inference mean that potentially sensitive data can be inferred from data that otherwise seems innocuous. Research in computer science has shown that social media likes of seemingly insensitive features, like liking Curly Fries or Hello Kitty, can be used to predict traits that are much more personal, like IQ, race, voting behavior, or drug use.
My research project “Digital Hermits,” joint with Avi Goldfarb (University of Toronto), Avery Haviv (University of Rochester), and Catherine Tucker (MIT), uses a theoretical model to examine how data sharing will evolve in the future. In our model, each user’s data consists of multiple personal features, some of which some users may prefer to keep private. Users can decide to share some of their data, all their data, or no data at all with the firm. Firms use accumulated data and machine learning to learn about the correlations between different dimensions of personal features.
This learning leads to data externalities across users. For example, suppose User A is an open book. They share so much information about themselves on a digital platform that the platform has a complete picture of their beliefs, likes, and dislikes from what they have shared. The more data from the User As of the world the platform accumulates, the better it can predict the correlations between different dimensions of user features.
User B, on the other hand, is more focused on privacy. Unfortunately for User B, the platform can use data from the User As of the world to make predictions about them. If enough people like User A share that they are both a Democrat and a cat owner, for example, all User B has to do is share a photo of their cat for algorithms to make inferences about User B’s political views and advertise accordingly. For User B, who never intended to share their political views, the effect of User A’s actions is a negative externality.
User B then faces a tough choice. Either User B accepts that there is little point in keeping just some data private, and User B chooses to become an open book just like User A. Or User B becomes what we dub a “digital hermit,” someone who shares no data at all. In the former case, User B suffers a privacy loss. In the latter case, User B foregoes some of the benefits of using the digital platform.
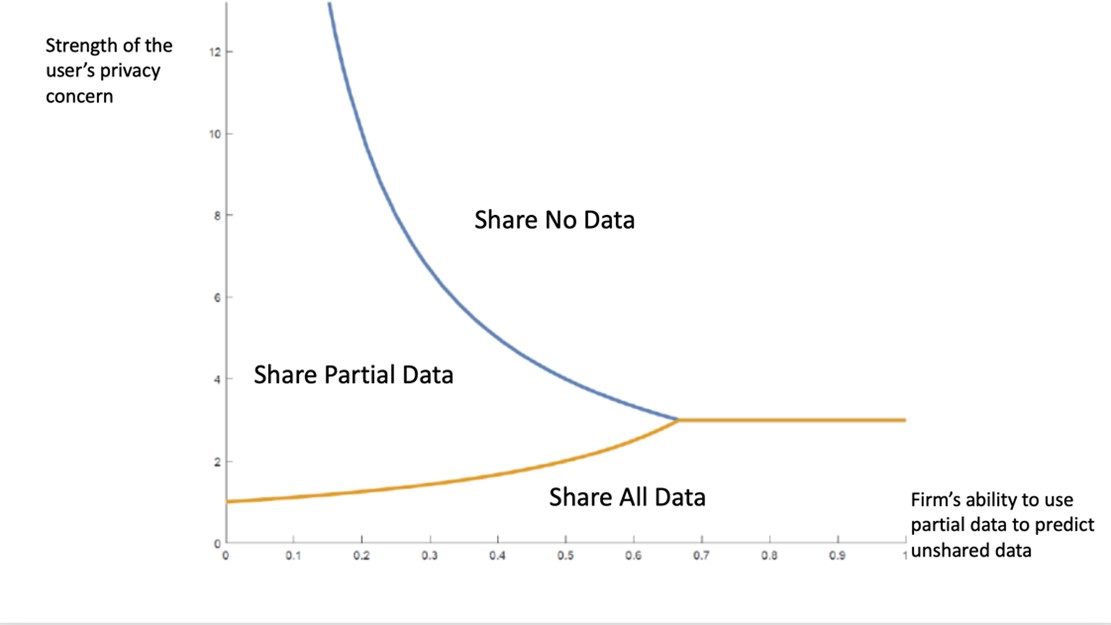
Our model shows that as a firm accumulates more data and refines its power of prediction, it has a polarizing effect among users.
Over time, new users sort themselves into two distinct groups, as the graphic below illustrates:
Full data sharers. For this group, partial data sharing no longer makes sense as firms get better at using partial data to predict unshared data. There is no point in hiding what will come to light anyway.
Digital hermits. Even in cases where firms offer more incentives for data sharing, this group of privacy-sensitive users chooses to share no data at all, even data that they do not consider private. Becoming a true digital hermit involves real commitment in this day and age. Avoiding all data sharing requires the user to delete all social media accounts, remove any smart speakers or listening devices from the home, and use a dumbphone.
This is a theoretical model, and users in the real world are not always tuned in to how their data is being used. Large-scale data breaches occasionally made headlines, but users don’t always relate these events to their personal lives unless they see evidence of data collection. If they discuss a product with a friend on a messenger service and see an ad for that product the same day, they may infer that the two events are connected.
But many of the ways in which firms could potentially use data are more subtle. If someone is listening to music that is correlated with anger, for example, they may not realize that advertising algorithms could be recalibrating to share news that will focus on outrage. While few people object to data collection about their music tastes, not many want to share their mood on a minute-by-minute basis with advertisers.
Whether we like it or not, the powerful current of Big Data is washing away middle ground when it comes to data privacy. We are heading in one of two directions: share our data without holding back or retreat entirely.

Jeanine Miklós-Thal is a professor in the Economics & Management and Marketing groups at Simon Business School. Her research spans industrial organization, marketing, and personnel economics.
Follow the Dean’s Corner blog for more expert commentary on timely topics in business, economics, policy, and management education. To view other blogs in this series, visit the Dean's Corner Main Page.
Related Blogs
-
 AGI could emerge within decades, bringing risks like job loss, misuse, misalignment, and even consciousness. Are we ready? Prof. Huaxia Rui explores the stakes.
AGI could emerge within decades, bringing risks like job loss, misuse, misalignment, and even consciousness. Are we ready? Prof. Huaxia Rui explores the stakes. -
 The new Department of Government Efficiency (DOGE) sparks debate. Is it streamlining bureaucracy or pushing privatization? Joseph Kalmenovitz unpacks its impact in this Q&A.
The new Department of Government Efficiency (DOGE) sparks debate. Is it streamlining bureaucracy or pushing privatization? Joseph Kalmenovitz unpacks its impact in this Q&A. -
 Understanding Creditor Rights and Their Impact February, 26 2025 | By Giulio Trigilia Creditor rights are often seen as a key driver of investment and economic growth, but research suggests the reality is more complex. While stronger protections can improve borrowing conditions in competitive
Understanding Creditor Rights and Their Impact February, 26 2025 | By Giulio Trigilia Creditor rights are often seen as a key driver of investment and economic growth, but research suggests the reality is more complex. While stronger protections can improve borrowing conditions in competitive -
 Online steering shapes how we shop, but is it fair? Simon professors Andras Miklos & Jeanine Miklos-Thal explore its ethical and economic impact in a new paper.
Online steering shapes how we shop, but is it fair? Simon professors Andras Miklos & Jeanine Miklos-Thal explore its ethical and economic impact in a new paper. -
 AI regulation must balance innovation and fairness. A recent keynote at Simon explored how competition and antitrust shape the evolving AI landscape.
AI regulation must balance innovation and fairness. A recent keynote at Simon explored how competition and antitrust shape the evolving AI landscape. -
 In this blog, Simon alumnus Josh Goldberg explains the 25-year journey of model risk management.
In this blog, Simon alumnus Josh Goldberg explains the 25-year journey of model risk management. -
 In this blog, Dean Sevin Yeltekin points to productivity as the key ingredient that drives US economic growth.
In this blog, Dean Sevin Yeltekin points to productivity as the key ingredient that drives US economic growth. -
 ChatGPT as a Marketing Assistant October 16 | By Professor Professor Paul Ellickson In this blog post, Professor Paul Ellickson describes the potential of machine learning and Generative AI tools to predict and improve the performance of marketing campaigns. Identifying and optimizing targeted
ChatGPT as a Marketing Assistant October 16 | By Professor Professor Paul Ellickson In this blog post, Professor Paul Ellickson describes the potential of machine learning and Generative AI tools to predict and improve the performance of marketing campaigns. Identifying and optimizing targeted -
 In this blog, Professor Alan Moreira unpacks the effects of policy promises on financial markets.
In this blog, Professor Alan Moreira unpacks the effects of policy promises on financial markets. -
 Professor Narayana Kocherlakota points to real wage decline to explain widespread voter pessimism about the U.S. economy.
Professor Narayana Kocherlakota points to real wage decline to explain widespread voter pessimism about the U.S. economy. -
 In this blog, Dean Sevin Yeltekin and Simon summer intern Defne Olgun take a closer look at the mismatch between economic indicators and voter perception.
In this blog, Dean Sevin Yeltekin and Simon summer intern Defne Olgun take a closer look at the mismatch between economic indicators and voter perception. -
 Partisan Regulatory Actions July 3 | By Vivek Pandey Professor Vivek Pandey presents evidence that the SEC treats firms differently based on political ideology. It’s no secret that Americans are more politically divided than ever. Intense political polarization has crept into every corner of society
Partisan Regulatory Actions July 3 | By Vivek Pandey Professor Vivek Pandey presents evidence that the SEC treats firms differently based on political ideology. It’s no secret that Americans are more politically divided than ever. Intense political polarization has crept into every corner of society